FastDFS 分布式文件系统
前置基础知识~
分布式文件系统是什么?
百度百科:分布式文件系统(Distributed File System)是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点(可简单的理解为一台计算机)相连。分布式文件系统的设计基于客户机/服务器模式。一个典型的网络可能包括多个供多用户访问的服务器。另外,对等特性允许一些系统扮演客户机和服务器的双重角色。例如,用户可以“发表”一个允许其他客户机访问的目录,一旦被访问,这个目录对客户机来说就像使用本地驱动器一样
通俗来说就是:
传统的文件系统管理的文件是存储在本机。例如我们在桌面创建个文件,或者删除文件都是在本机上操作,而分布式文件系统管理的文件存储在很多机器上,这些机器通过网络相互连接,被统一管理。无论是上传还是下载文件都通过管理中心来访问。如图:
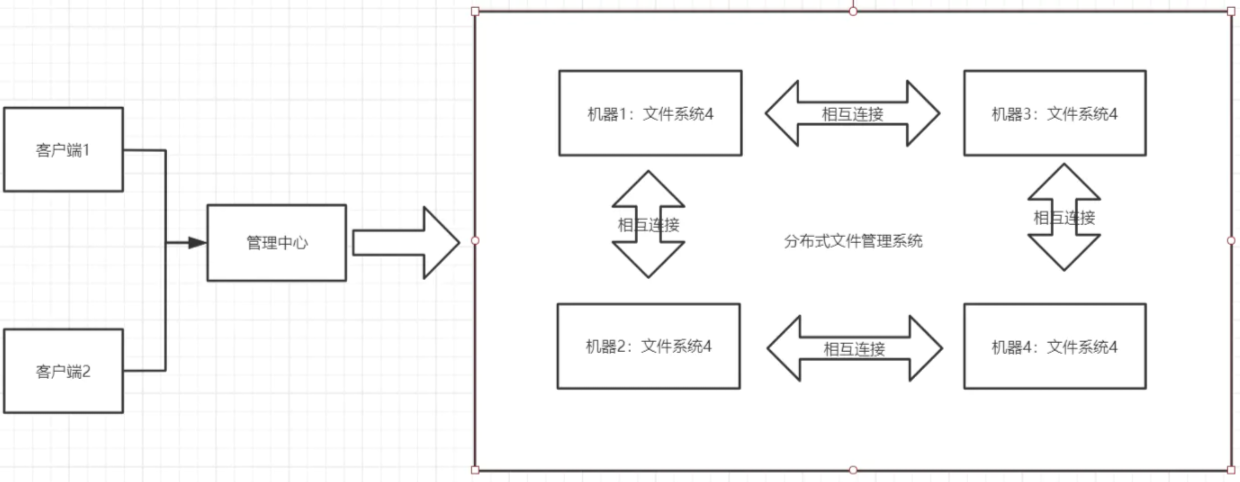
分布式文件系统类型
分布式文件系统类型有很多,主流的几种类型如下:
NFS:最早由 Sun微系统公司作为TCP/IP网上的文件共享系统开发。Sun公司估计大约有超过310万个系统在运行NFS,大到大型计算机、小至PC机,其中至少有80%的系统是非Sun平台
AFS:AFS 是一种分布式的文件系统用来共享与获得在计算机网络中存放的文件。AFS 使得用户获得网络文件就像本地机器般方便。AFS文件系统被称为 “分布式” 是因为文件可以分散地存放在很多不同的机器上,但这些文件对于用户而言是可及的,用户可以通过一定的方式得到这些文件。
GFS:Google 公司为了存储海量搜索数据而设计的专用文件系统。是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,并提供容错功能。它可以给大量的用户提供总体性能较高的服务
KFS:是开始软件自主研发基于 JAVA的纯分布式文件系统,通过 HTTP WEB 为企业的各种信息系统提供底层文件存储及访问服务,搭建企业私有云存储服务平台
DFS:DFS 是 AFS 的一个版本,作为开放软件基金会(OSF)的分布式计算环境 DCE 中的文件系统部分。
如果文件的访问仅限于一个用户,那么分布式文件系统就很容易实现。可惜的是,在许多网络环境中这种限制是不现实的,必须采取并发控制来实现文件的多用户访问,表现为如下几个形式:
- 只读共享:任何客户机只能访问文件,而不能修改它,这实现起来很简单。
- 受控写操作:采用这种方法,可有多个用户打开一个文件,但只有一个用户进行写修改。而该用户所作的修改并不一定出现在其它已打开此文件的用户的屏幕上。
- 并发写操作:这种方法允许多个用户同时读写一个文件。但这需要操作系统作大量的监控工作以防止文件重写,并保证用户能够看到最新信息。这种方法即使实现得很好,许多环境中的处理要求和网络通信量也可能使它变得不可接受
FastDFS 是什么?
FastDFS 是一个开源的轻量级分布式文件系统,它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以中小文件(建议范围:4KB < file_size <500MB)为载体的在线服务,如相册网站、视频网站等。
FastDFS 架构图 🤔
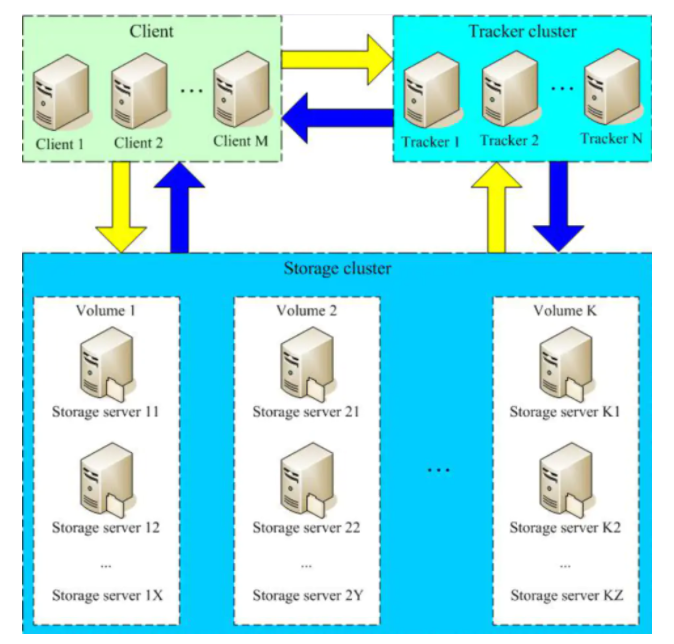
Client 是我们去连接 FastDFS 的客户端。例如我们是 Java客户端去连接,那么 Client就是 Java客户端
Track Server 跟踪服务器 相当于我们的管理中心(注册中心),主要做调度工作,负责调度 Storage 节点和 Client 之间的通信。同时在访问上也有负载均衡的作用,以及记录 Storage 节点运行状态。是连接 Client 和 Storage Server 的枢纽
Storage Server 存储服务器 主要存储文件和元数据(meta data),每一个 Storage 都会启动一个单独的线程向跟踪服务器集群(Track cluster)里面的 Track 汇报其状态信息。例如磁盘的使用情况,文件同步情况,上传下载次数等等。这其实跟微服务思想很相似。每一个服务向注册中心发送心跳。
Group 文件组,一个组里面包含了多台 Storage Server,加入上传到同一组的内的任何个一台机器后,同组内其他机器就会同步到其他信息上,相当于其他机器就是这台机器的副本。达到文件备份效果。不同的组保存的数据是独立的,相互不干扰,不通信。假如当所有的组文件存储满了,我们还可以再增加组,这就是水平扩容。
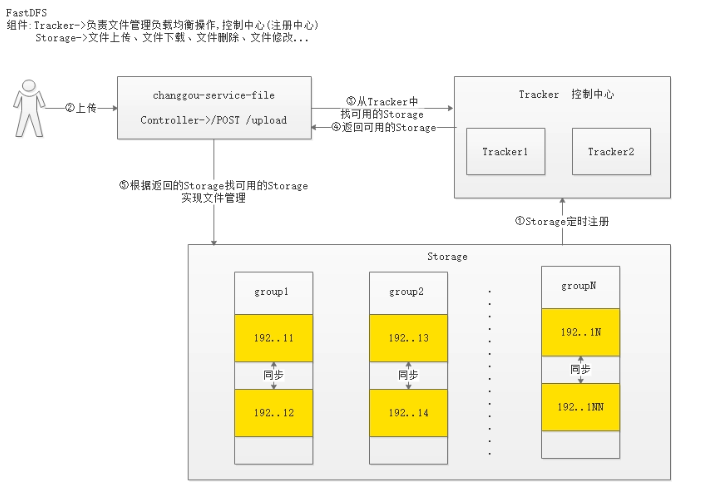
Track cluster 跟踪服务器集群,多台跟踪服务器组成
Storage cluster 存储服务器集群,多个组构成,即以组为单位,多个组才是集群,而一个组里面的 Storage 之间是同步的(容灾)
使用 Docker 搭建环境
先拉取这个镜像到本地
docker pull morunchang/fastdfs
运行 tracker
docker run -d --name tracker --net=host morunchang/fastdfs sh tracker.sh
运行 storage
docker run ‐d ‐‐name storage ‐‐net=host ‐e \
TRACKER_IP=tracker的IP地址:22122 ‐e GROUP_NAME=group名 \
morunchang/fastdfs sh storage.sh
- 使用的网络模式是
–net=host,替换为你机器的 IP 即可 - 组名,即 storage的组
- 如果想要增加新的 storage 服务器,再次运行该命令,注意更换新组名
配置开启自启
docker update --restart=always tracker
docker update --restart=always storage
再配置一下 Nginx
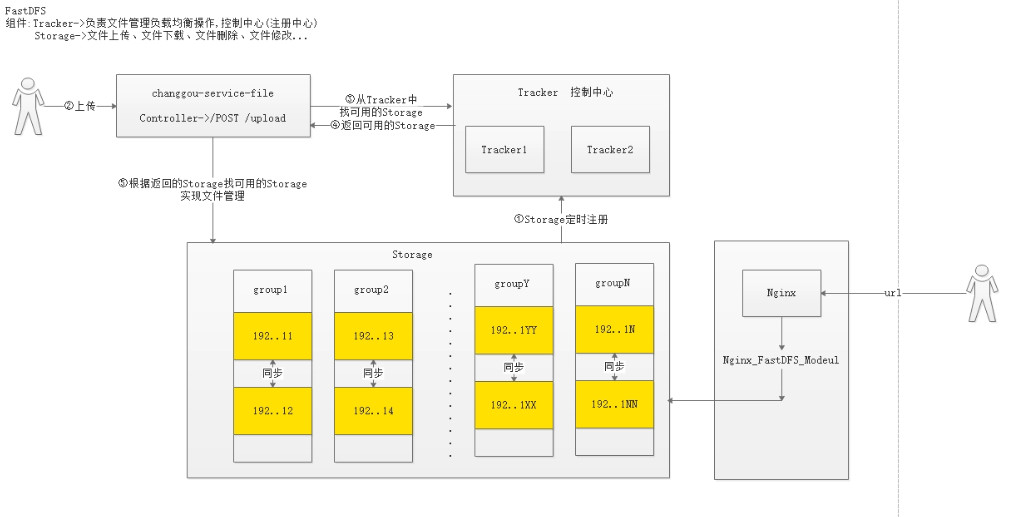
注意:它是通过访问 nginx 的 Fast 模块来访问 Fast Server 的,所以还需要再配置一下 Nginx
修改 nginx 的配置,进入 storage 的容器内部,修改 nginx.conf
docker exec ‐it storage /bin/bash
进入后:
vi /data/nginx/conf/nginx.conf
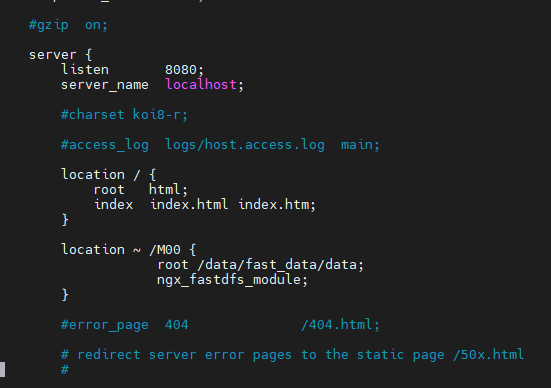
添加以下内容(如果已经存在就不用管了~):
location ~ /M00 {
root /data/fast_data/data;
ngx_fastdfs_module;
}
退出容器:
exit
重启 storage 容器:
docker restart storage
设置禁止缓存
当浏览器访问过 Storage 中的资源后,即便将 Storage 中的资源已经被删除了,浏览器还是会访问缓存中数据,那如果我们不想这样,就可以配置一下禁止缓存。还是上面的步骤,在里面添加一行内容:
location ~ /M00 {
add_header Cache-Control no-store; #告诉浏览器不要缓存数据
root /data/fast_data/data;
ngx_fastdfs_module;
}
运行时目录结构
Storage Server

Tracker Server

文件上传流程
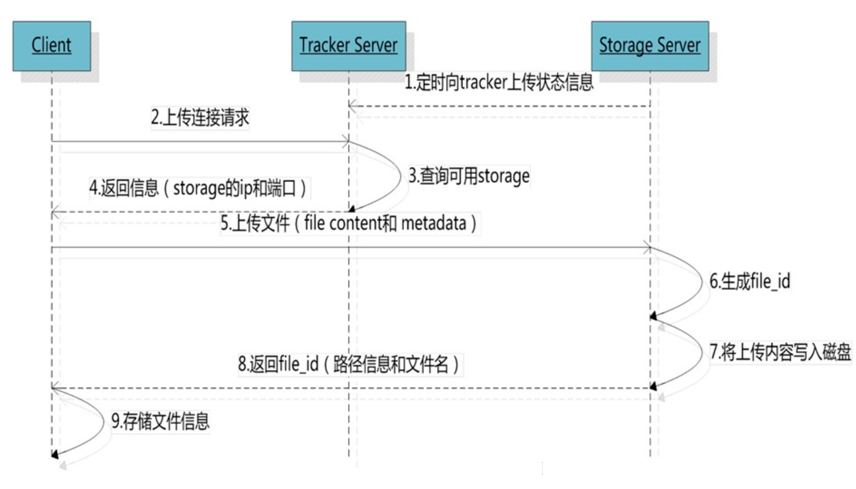
执行流程
具体的执行流程如下所示:
1、Client 首先向 Tracker 发送获取上传目标 Storage 信息的请求,不带参数;
2、Tracker 返回一台可用的 Storage 信息(storage IP 和端口)
3、选择 Storage Path(磁盘):分配好 Storage Server 后,客户端先将 file content 和 metadata 发送到 storage,然后向 Storage 发送写文件请求,Storage 为文件分配一个数据存储目录;
4、生成 FileID:选定存储目录之后,Storage 会为文件生一个 fileID,由 Storage Server IP、文件创建时间、文件大小、文件crc32 和一个随机数拼接而成,然后将这个二进制串进行 base64 编码,转换为可打印的字符串;若引入小文件合并机制,此 ID 增加16个字节,即 trunk file id、文件在 trunk file 内部的 offset 、文件占用的存储空间大小(字节对齐及删除空间复用,文件占用存储空间 >= 文件大小)
5、选择两级目录:每个存储目录下有两级 `256256` 的子目录,Storage 会按文件 fileID 进行两次 hash(猜测),路由到其中一个子目录,然后将文件以 fileID 为文件名存储到该子目录下。*
6、生成文件名:当文件存储到某个子目录后,即认为该文件存储成功,接下来会为该文件生成一个一个文件名,文件名由 group、存储目录、两级子目录、fileID、文件后缀名(由客户端指定,主要用于区分文件类型)拼接而成。
上传模板的选取规则
选取上传目标 Volume 规则:
- Round robin:所有 Volume 间轮询;
- Specified group:指定一个 Volume;
- Load balance:剩余空间多的 Volume 优先;
选取上传目标 Storage 规则:
- Round robin:Volume 内所有 Storage 中轮询;
- First server ordered by ip:按 ip 排序;
- First server ordered by priority:按优先级排序(优先级在 Storage 上配置);
选取上传目标 Storage path 规则:
- Round robin:多个存储目录轮询;
- Load balance:剩余存储空间最多的优先;
返回的文件 ID
客户端上传文件后存储服务器将文件 ID 返回给客户端,此文件 ID 用于以后访问该文件的索引信息。文件索引信息包括:组名,虚拟磁盘路径,数据两级目录,文件名。
如下所示:

- 组名:文件上传后所在的 Storage 组名称,在文件上传成功后有 Storage 服务器返回,需要客户端自行保存。
- 虚拟磁盘路径:Storage 配置的虚拟路径,与磁盘选项 `store_path
对应。如果配置了 store_path0 则是 M00,如果配置了 store_path1 则是 M01,以此类推。(M00虚拟路径指向了 Storage 组中某个节点的硬盘地址,比如etc/fdfs/data`)* - 数据两级目录:Storage 服务器在每个虚拟磁盘路径下创建的两级目录,用于存储数据文件。
- 文件名:与文件上传时不同。它是由存储服务器根据特定信息生成,文件名包含:源存储服务器 IP 地址、文件创建时间戳、文件大小、随机数和文件拓展名等信息。(就是上面最后那个
wKgDrE...)
那为什么要产生这么奇怪的文件名呢?
# 先进到容器里面去看
docker exec -it storage bash
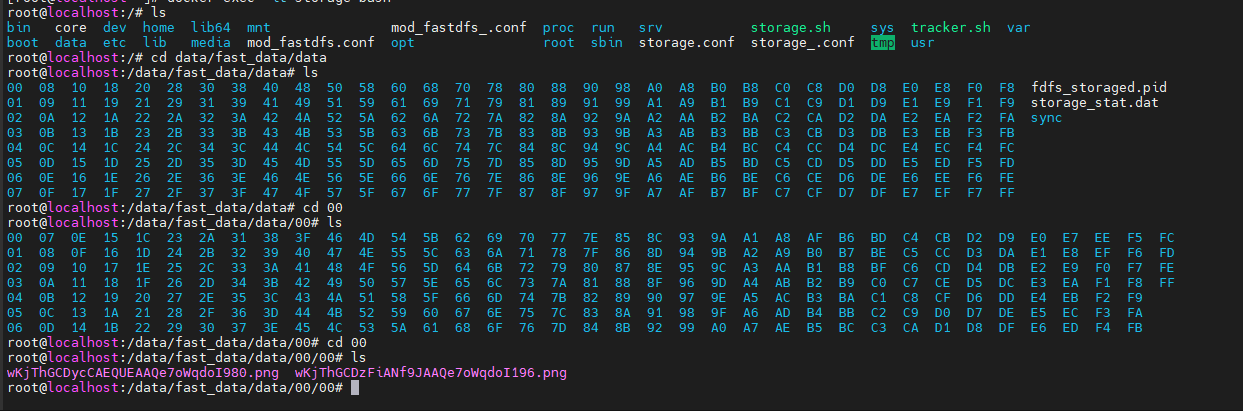
cd data/fast_data/data

可以发现这些文件夹的名字都很奇怪,其实文件就是通过文件名的哈希值来在这里找到文件对应的文件夹的(即文件名决定它存在哪个文件夹)
比如下面这个刚上传上去的文件(具体怎么上传可以看对应客户端上传那篇笔记,例如 SpringCloud 的那个)
http://192.168.211.132:8080/group1/M00/00/00/wKjThGCDzFiANf9JAAQe7oWqdoI196.png
可以看到它由 00/00 这两层,进去可以发现文件确实就在这里面
文件下载流程

1、Client 向 Tracker 发送获取目标文件的请求,参数为文件标识(卷名和文件名);
2、Tracker 返回指定卷下一台可用的 Storage;
3、Client 直接与目标 Storage 通讯完成文件下载;
参数形式如下:
volume0/M00/00/02/Cs8b8lFJIIyAH841AAAbpQt7xVI4715674
这些参数的作用:
- volume0:组名
- M00:磁盘名
- 00/02:目录
- Cs8b8lFJ...:文件名,采用 base64 编码,信息包含源 storage server Ip、文件创建时间、文件大小、文件 CRC32 效验码和随机数
tracker 选择 volume 内可读的 storage 规则:
1、首选文件名编码中包含的源头 storage;
2、文件创建时间戳(文件名中包含)=storage被同步到的时间戳(binlog中包含) && (当前时间-文件创建时间) > 文件同步所需最大时间;
3、文件创建时间戳 < storage被同步到的时间戳;
4、(当前时间-文件创建时间戳) > 同步延迟阈值;
Reference ~
参考资料 FastDFS 项目地址 参考资料 分布式文件系统(一) - FastDFS介绍与普通安装 参考资料 FastDFS学习(一)--基础知识及文件上传、下载和同步原理分析